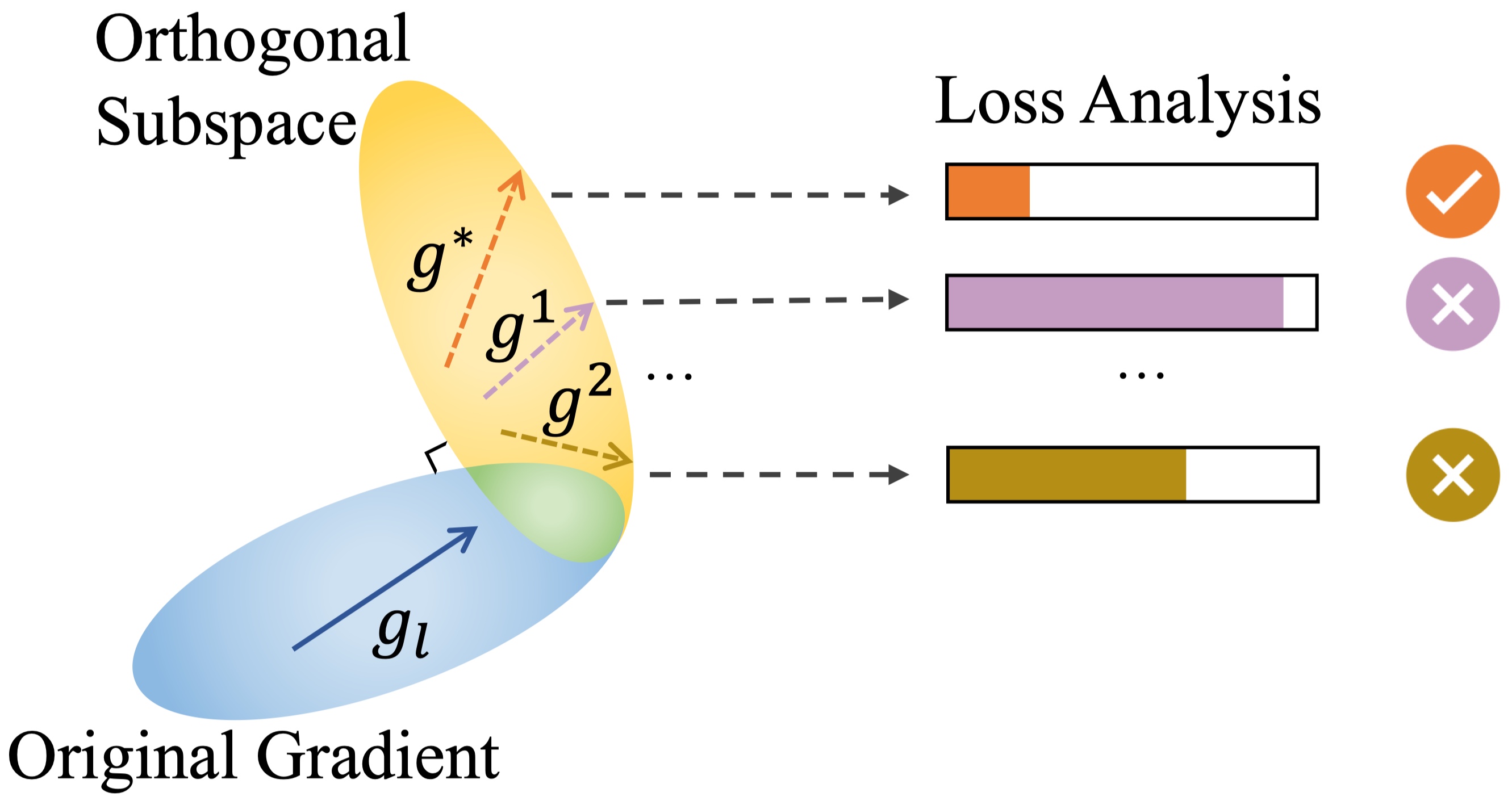
Intuition
In high-level, CENSOR samples gradients in a subspace that is orthogonal to the original gradient layer by layer and select the one that achieves the lowest loss.
Abstract
Federated learning collaboratively trains a neural network on a global server, where each local client receives the current global model weights and sends back parameter updates (gradients) based on its local private data. The process of sending these model updates may leak client's private data information. Existing gradient inversion attacks can exploit this vulnerability to recover private training instances from a client's gradient vectors. Recently, researchers have proposed advanced gradient inversion techniques that existing defenses struggle to handle effectively. In this work, we present a novel defense tailored for large neural network models. Our defense capitalizes on the high dimensionality of the model parameters to perturb gradients within a subspace orthogonal to the original gradient. By leveraging cold posteriors over orthogonal subspaces, our defense implements a refined gradient update mechanism. This enables the selection of an optimal gradient that not only safeguards against gradient inversion attacks but also maintains model utility. We conduct comprehensive experiments across three different datasets and evaluate our defense against various state-of-the-art attacks and defenses.
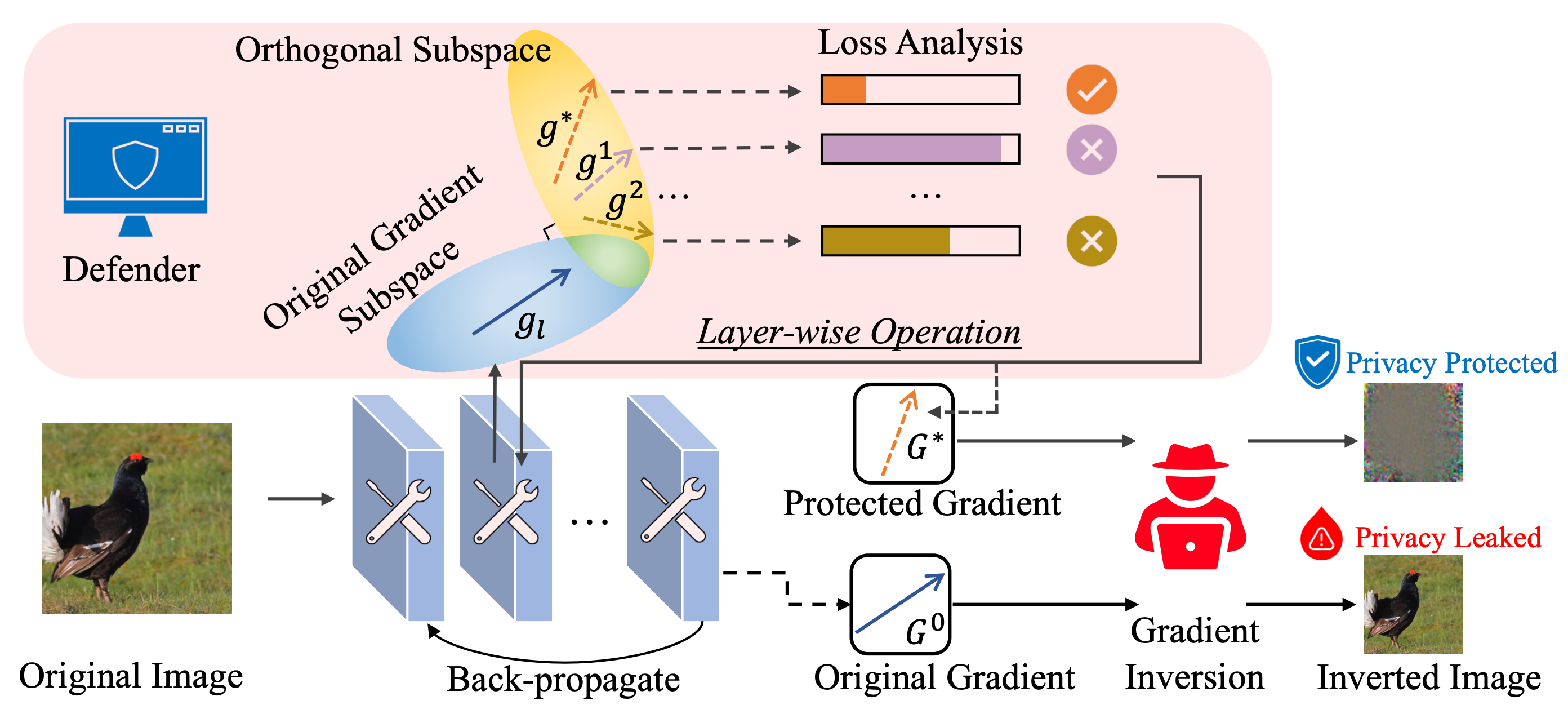
CENSOR perturbs gradients within a subspace orthogonal to the original gradient.
Performance
We evaluate the performance of CENSOR against five attacks and compares it with four state-of-the-art defenses, across different batch sizes and three widely-used datasets.
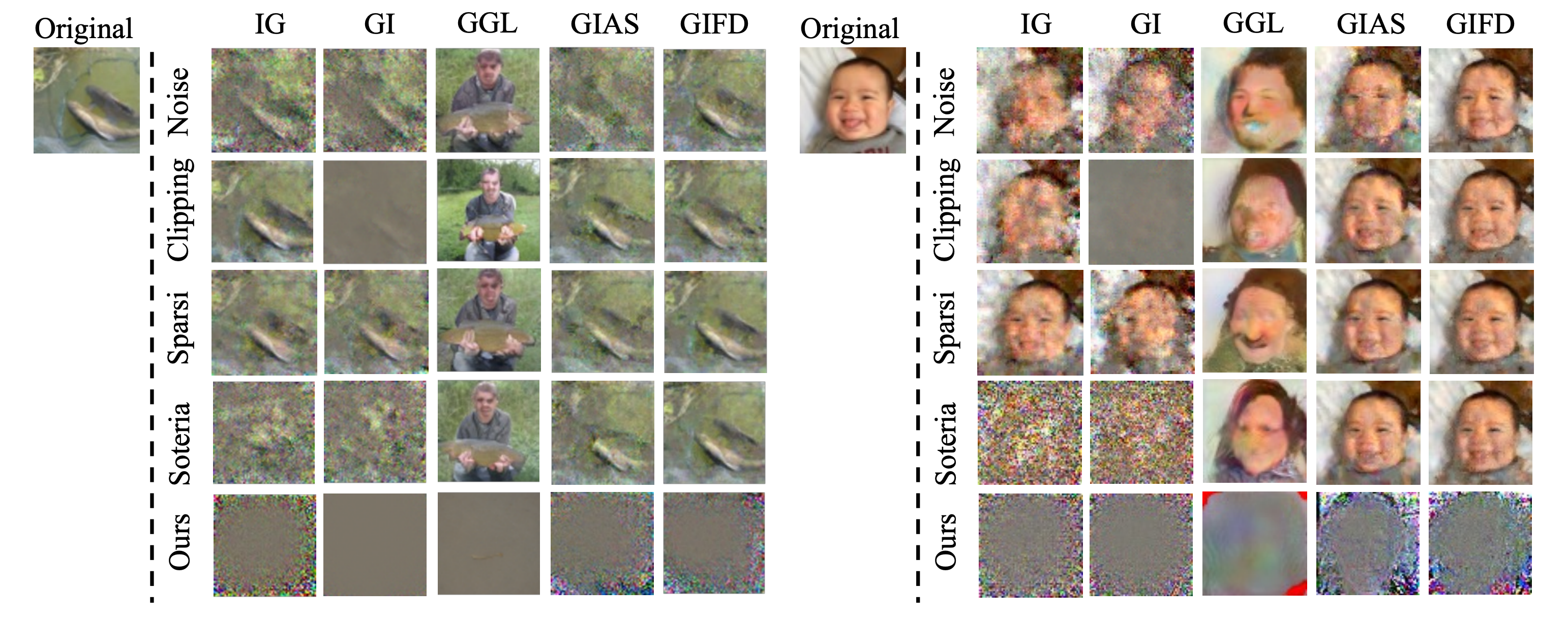
Qualitative evaluation of various attack inversions under existing defenses.
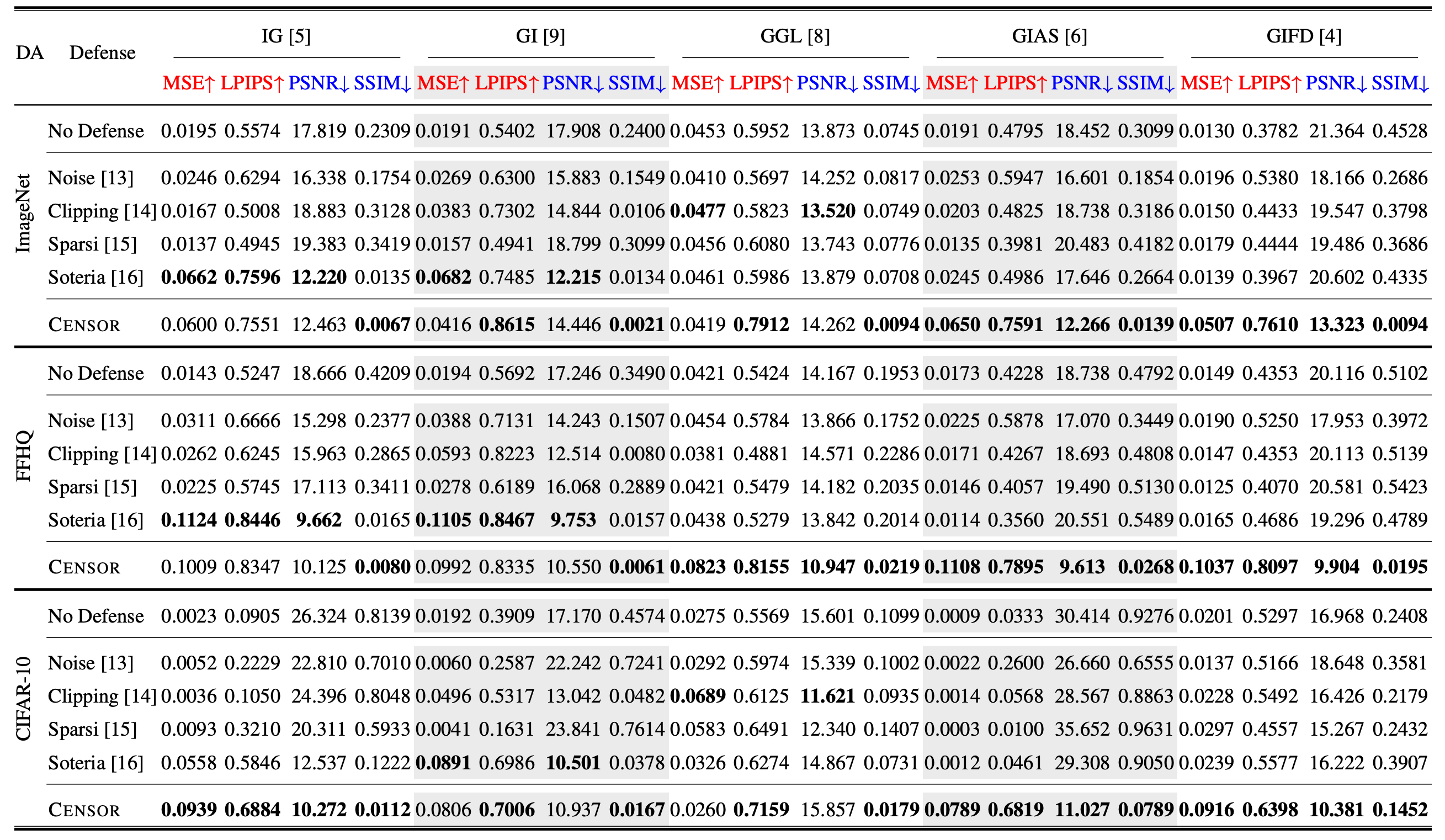
Quantitative evaluation of various defense methods against existing attacks. (An upward arrow denoting the higher the better, a downward arrow denoting the lower the better.)
BibTeX
@inproceedings{zhang2025censor,
title={CENSOR: Defense Against Gradient Inversion via Orthogonal Subspace Bayesian Sampling},
author={Zhang, Kaiyuan and Cheng, Siyuan and Shen, Guangyu and Ribeiro, Bruno and An, Shengwei and Chen, Pin-Yu and Zhang, Xiangyu and Li, Ninghui},
booktitle={32nd Annual Network and Distributed System Security Symposium, {NDSS} 2025},
year = {2025},
}